我们想搭建一个关于游戏的推荐系统,给用户推荐有趣、好玩的游戏。起初在还没有用户的情况下一般采用基于内容推荐,然而要还原游戏的真实面貌,清洗垃圾评论是必不可少的。下面讲讲我们在这其中的一系列尝试,处理代码戳这里
预处理
我们先从渠道应用宝里面获取了很多游戏的数据,其中包括评论、用户评分。这些评论有内容简短、重复出现等特点。因此我们先进行了预处理
- 处理评论内容html 反转义内容、繁体转简体、去除标点符号
- 并选出长度大于5 的评论
- 去除重复三次以上的评论
接下来我们手动标记了1000条评论数据(这个样本有点少,至少要10000条的),0代表无用评论,1代表普通评论。分类模型选用了逻辑回归方法,但是如何表达样本数据使其适用分类模型是重要考虑得。我们尝试了四种表示方法
- 词袋模型,就是基于样本预料集的词频矩阵,各样本维度相同,元素是对应词的词频
- tf-idf,利用tf-idf 优化词袋模型,只用认为是样本关键词来表示样本,而不是全部词汇
- word2vec,用向量表示每个词汇,求出样本全部词汇的平均值向量表示该样本
- 端到端方式,利用卷积神经网络CNN学习语法特征
词袋模型
词袋模型就是用词汇出现的次数来表示每个词,忽略了词汇在句子中出现的顺序,只关心词出现的次数。要求先得到全部样本的语料集,再求出每个样本基于语料集的词频矩阵。
用词袋模型表示样本之后,可视化数据观察类别分布是否明显。语料的维度很大要利用PCA特征降维技术把数据降到2个维度。
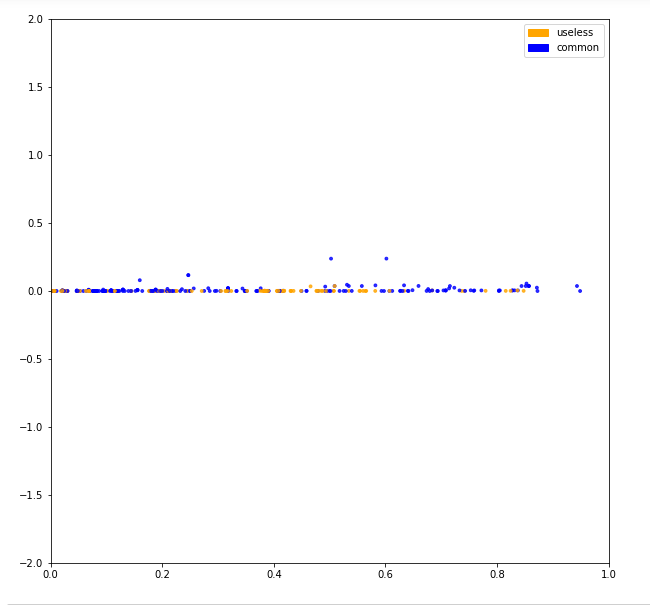
可以看到分类效果并不明显。接下来看看分类模型的效果怎么样。1
2
3
4
5
6
7
8from sklearn.linear_model import LogisticRegression
# 逻辑回归 分类器
clf = LogisticRegression(C=30.0, class_weight='balanced', solver='newton-cg',
multi_class='multinomial', n_jobs=-1, random_state=40);
clf.fit(X_train_counts, y_train);
y_predicted_counts = clf.predict(X_test_counts);
y_predicted_counts;
结合混淆矩阵来检验模型
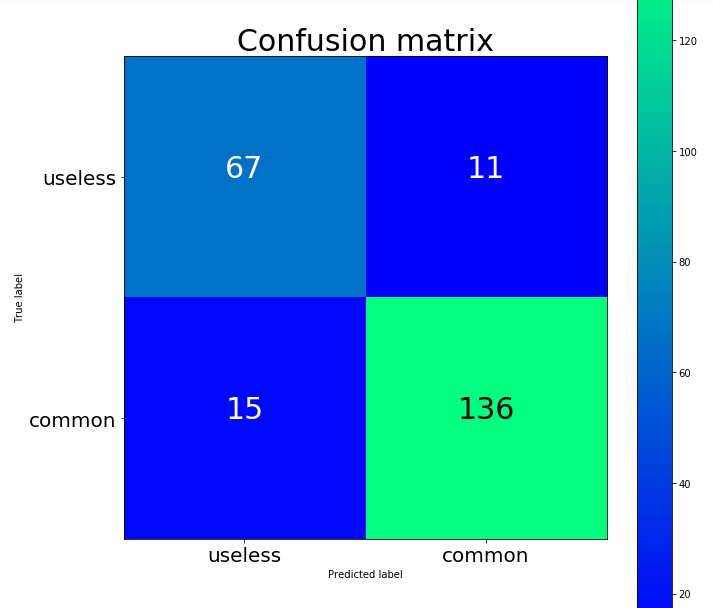
1 | accuracy = 0.886, precision = 0.888, recall = 0.886, f1 = 0.887 |
我们还可以把逻辑回归模型系数的大小看成词汇的权重,系数越大代表词的权重越大。选择影响分类权重最大的词汇,看是否和实际情况相符。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23{'bottom': [
(-1.9233468753654832, '想玩过'),
(-1.9699934849413354, '东西'),
(-1.9936101307589726, '一科'),
(-2.0586707932196653, '完整版'),
(-2.2143741219571784, '第六感'),
(-2.2944339277405317, '平台'),
(-2.296290346516122, '张立根'),
(-2.5400863161740292, '全过'),
(-2.6306392117308213, 'f2'),
(-3.1548797624472003, 'cnm')],
'tops': [
(2.1516471108530144, 'lajibamxigyegei'),
(2.1803090306315083, '界面'),
(2.211154149794893, '根本'),
(2.2950592487795909, '下载'),
(2.507806444700754, '广告'),
(2.513095684570573, '不错'),
(2.8654346669109865, '好难'),
(2.9219171750081423, '样儿'),
(3.092310924958777, '老是'),
(3.2120104179278735, '不能')
]}
tf-idf
词频逆文档(tf-idf)是找出样本关键词的一种算法,它认为出现频率最高的词就是样本关键词,为了排除那些常用词比如我、的、也的干扰,还必须是在其他样本出现频率较低的词。据此可得$tf-idf$的表达式,词汇$w$在样本出现频率$n$,样本总词汇$N$,样本总数$D$,包含$w$的样本总数$D_{in}$,
$$tf-idf={n \over N} \log_2{D \over (1 + D_{in})}$$
tf-idf 对词袋模型的优化之后,分类模型的准确率有少量改善。详见源码。从效果来看感觉词袋模型不太适合短评论。
word2vec
用上面词频表示词汇的方法很容易遇到语料中缺省的词,这样模型就没法进行分类。Word2Vec 是一种为每个单词生成词向量的技术。通过阅读大量文本,它能够学到并记住那些倾向于在相似语境中出现的词汇。经过足够多的数据训练,词汇表中的每个单词都会生成一个300维的向量,由意思相近的单词组成。
我使用word2vec表示词汇,要先训练自己的语料库。用向量表示每个词汇,求出样本全部词汇向量的平均值表示该样本。还是用PCA降维技术可视化到界面观察类别分布情况。
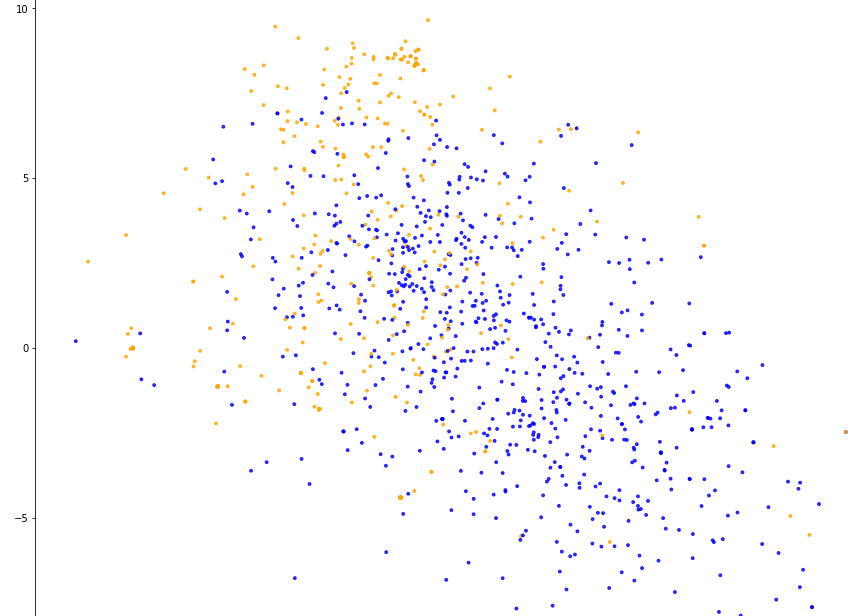
可以看到类别区分更加明显,分类器分类效果也有改善。
CNN
前面介绍了快速高效地获得句子嵌入的方法,然而由于省略词汇的顺序,我们也忽略了句子中所有的语法信息。CNN 能够考虑单词的顺序,能很好地学习到句子中哪些单词的序列特征影响到目标预测。处理代码戳这里
效果如下,

参考文献
欢迎大家给我留言,提建议,指出错误,一起讨论学习技术的感受!
