k-means 聚类
k-means聚类是无监督学习,训练数据集都是未添标签的(不知类别)。就连数据集最终要分成几类都是不知道的。聚类和分类的不同是,后者必须对分类的目标事物必须是已知的。
聚类算法是根据样本之间的距离(相似度)来分类的,判断是否属于同一个簇。常见的计算距离的算法有欧式距离,曼哈顿距离和余弦相似性距离等。其中欧式距离,在二维平面上就是两点距离公式。
应用
假设有如下数据集,现在要用k-means 聚类把它进行分类1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
161.658985 4.285136
-3.453687 3.424321
4.838138 -1.151539
-5.379713 -3.362104
0.972564 2.924086
-3.567919 1.531611
0.450614 -3.302219
-3.487105 -1.724432
2.668759 1.594842
-3.156485 3.191137
3.165506 -3.999838
-2.786837 -3.099354
4.208187 2.984927
-2.123337 2.943366
0.704199 -0.479481
............
k-means的算法核心是
- 把上面数据放在 二维矩阵dataSet
- 指定想把数据集分为 k 类
- 随机生成 k个质心$A_1(x_1, y_1)$,$A_2(x_2, y_2)$….$A_n(x_n, y_n)$,生成方法是选出矩阵第一列$min_1$, $max_1$,选出第二列$min_2$,$max_2$,在$[min_1$,$max_1]$ 随机产生$x_1$,在[$min_2$,$max_2]$生成$y_1$,得出$A_1(x_1, y_1)$。同理生成其他质心
- 遍历全部数据点,离哪个质心距离最近,数据就归为那类。建立一个二维矩阵存储各个数据分类情况和误差(离质心距离)
- 更新质心:计算每个类所有点的均值作为质心
- 重新遍历全部数据点,若没有一个数据归类改变isChange = false,则聚类结束
最后聚类结束之后的结果
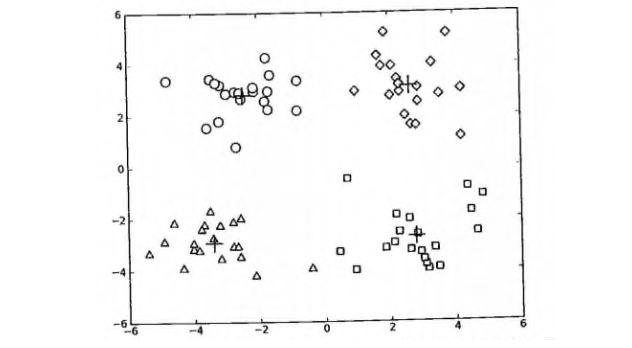
二分 k-means
二分k-means 是对k-meas 的改进
参考文章
欢迎大家给我留言,提建议,指出错误,一起讨论学习技术的感受!
