决策树
决策树是分类算法,一个未贴标签(未知类别)的新数据(含多个特征),通过问多个问题(问题是:特征,答案:是或者否),最终问题问完,判断出新数据类别。问问题的流程基于决策树。
所以训练决策树的步骤一般是,先有已知类别的数据集、选择特征问问题生成决策树、测试决策树。决策树模型生成之后就可以用于分类没贴标签的数据集。
要理解决策树算法,首先要知道熵的概念,是信息论里面的知识,用来形容信息的混乱程度。信息越有序则熵值越低,越混乱熵值越大。熵的计算公式,其中p(x) 代表类别x在信息整体中出现的概率
$$H=-\sum_{i=1}^np(x_i)\log_2p(x_i)$$
比如计算下面数据的熵值1
2
3
4
5
6# yes 代表是鱼类,no 代表不是鱼
1, 1, 'yes'
1, 1, 'yes'
1, 0, 'no'
0, 1, 'no'
0, 1, 'no'
上面信息整体中有鱼类x1,非鱼类x2,出现的概率分别为2/5,3/5,所以上面的信息熵为1
- 2/5log(2/5) - 3/5(log3/5)
应用
用决策树算法来判断生物是否鱼
收集数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17特征1(不浮出水面是否能活) 特征2(是否有脚蹼) 类别(是否鱼)
yes yes yes
yes yes yes
yes no no
no yes no
no yes no
# 变成向量的形式:
dataSet = [
[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']
]
# labels 存储的是特征,即决策树的问题
labels = ['no surfacing', 'flippers']分析数据:这里的数据集不是连续的,都是0,1 离散数据,这步可以省略
- 构造算法,选择labels 中哪个特征来问题呢,全部特征集合labels存储,逐一尝试,计算分类前后香农熵,选取信息增益(熵差)最大的特征x,划分后的子集去除特征x, 集合labels去除特征x。就这样一直递归下去,直到每个子集的只有一种类别,即信息熵为0
假设我们在特征1和特征2选特征1来分类,即问一个问题(此新数据不浮出能活吗),安照答案(即特征值yes no )得到分类,并计算该数据集的香农商。分类后
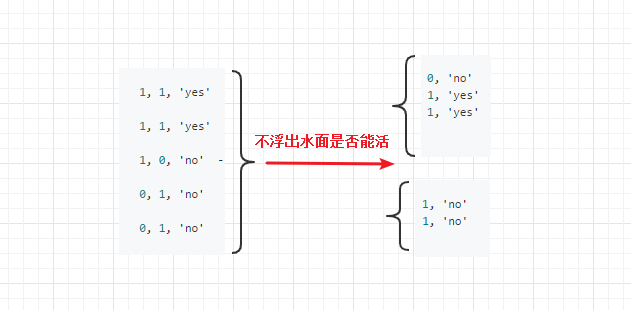
由特征1分类,子集去掉特征1,计算数据集香农熵1
2
3
4
5#分类前香农熵:
- 2/5log(2/5) - 3/5(log3/5)
#分类后香农熵,
- 3/5*(2/3log(2/3)+1/3log(2/3)) - 2/5*(1log1)
分类后香农熵,3/5 表示该子集占全集,2/3表示 yes在子集占比。若子集类别一致,香农熵为 0
- 最后形成的决策树
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}

参考文献
欢迎大家给我留言,提建议,指出错误,一起讨论学习技术的感受!
