K-近邻算法
KNN用于分类,先有已知类别的数据集,输入一个样本,利用K-近邻算法得出该样本的类别, 一个样本包括特征、类别等数据。KNN 程序代码戳这里
kNN原理
- 带有标签(类别)样本数据集,包含样本特征
- 输入没有标签的新数据,将新数据和样本集数据对应的特征进行比较
- 计算新数据和样本集的欧式距离
- 取出最小的前k个,取出这k个样本中出现次数最多的类别,作为新数据的类别标签
应用
优化约会网站的配对效果,数据样本包括:前三个是特征,最后一个是类别1
2
3
4
5飞行常客历程数 玩游戏占时间比 每周冰淇淋消费公升数 类别
40920 8.326976 0.953952 3
14488 7.153469 1.673904 2
26052 1.441871 0.805124 1
.....
其中类别 1不喜欢的人 2魅力一般的人 3极具魅力的人,最终输入新数据,用 K-近邻 判断其类别。
KNN的使用过程如下,
- 收集数据:提供上面格式的文本数据
- 准备数据:python解析文本,返回一个矩阵A包含样本集特征,一个类别矩阵B
- 分析数据:Matplotlib画二维散点图,剔除一些点
- 训练数据:此步骤不适合K-近邻算法,和测试工作一样
- 测试算法:取数据集(已知类别)一些点,测试是否分类正确,否,标记一个错误
- 使用算法:产生简单命令行程序,输入一个新数据特征,输出其类别
分析数据时取特征1、特征2为x轴,y轴,将各个样本数据在图中显示。不同类别用不同颜色,以便观察是否适用KNN 。效果如下图,
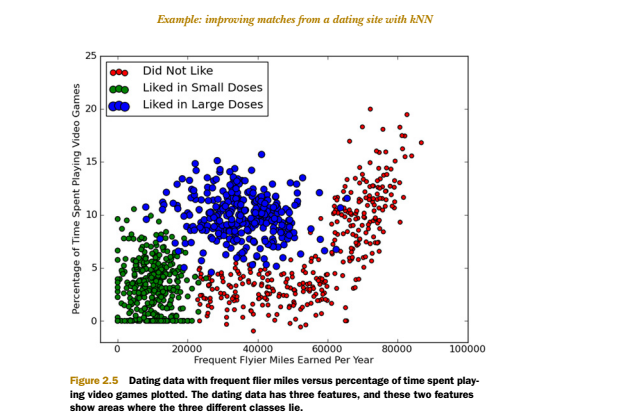
计算样本距离前,可以先把各个特征的数据进行归一化,即把该特征的值固定在一个范围里。归一化可以消除特征之间数据量级不同导致的影响,比如上面的飞行常客历程数上万的数值,而玩游戏占时间比只是几十,两者相差太大;同时归一化可以保证程序运行收敛加快。
一个样本相当矩阵A的一行,计算距离可以先把各个特征(即A的各个列)归一化到[0, 1]的范围,采用线性函数转换的方法。做法是取出该列min、max,把x归一化后y为
y = (x-min)/(max-min)
归一化的其他方法还有对数函数转换,反余切函数转换
参考文章
欢迎大家给我留言,提建议,指出错误,一起讨论学习技术的感受!
